I november i fjor fikk jeg endelig installert solceller på taket etter lengre ventetid. Målet er å utnytte et område som ellers ville vært ubenyttet, til å generere egen strøm. På lengre sikt har jeg ambisjoner om at dette skal bli en lønnsom investering. Men det er verdt å merke seg at med dagens lave strømpriser, er det høyst usikkert om investeringen vil betale seg.
Solcellene på taket sender strømmen inn i en inverter, eller likeretter som omformer likestrøm (DC) til vekselsstrøm (AC) tilsvarende det man ellers får i kontakten. Det meste går til eget forbruk, og det som eventuelt blir til overs selges sømløst til andre i nabolaget.
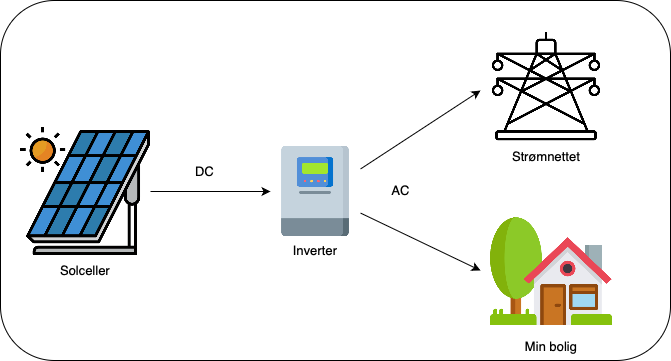
Det er imidlertid et annet aspekt ved en inverter jeg som IT person synes er spennende. Den kan også levere fra seg data om alt fra effekt, produksjon pr dag, totalproduksjon gjennom anleggets levetid og mye mer. Her er det med andre ord potensiale for et sideprosjekt.
I denne bloggposten skal jeg forklare hvordan jeg har laget et nettsted jeg pompøst nok har kalt solkongen.cloud. Her kan enhver som ønsker følge produksjonen fra mitt tak. Denne løsningen har jeg utelukkende bygget ved å benytte serverløs teknologi i alle ledd, fordi jeg ønsket å se hva som må til for å sette det opp på denne måten. Jeg har benyttet Amazon AWS sine serverløse tjenester, men både Microsoft, Google og andre aktører har lignende tjenester.
¶Hva betyr serverløs teknologi
Serverløs teknologi, bedre kjent som “serverless” på engelsk, tar skytjenester et steg videre. I tradisjonelle skytjenester setter brukere opp servere for å kjøre alt fra webtjenester til databaser. Disse serverne må konfigureres og delvis administreres.
I en serverløs tilnærming derimot, er du ikke selv ansvarlig for serveradministrasjon. I stedet kjører du funksjoner av kode, bruker databaser, og lagrer filer i skyen uten å behøve å vite hvilken maskin de kjører på eller hvordan du skal skalere tjenesten ved økende last.
For å trekke en analogi til kraftbransjen: Med serverløs teknologi kan datakraft og tjenester sammenlignes med å bruke strøm rett fra veggen. Vi som sluttbrukere har vanligvis ingen formening om hvilket vannkraftverk i Norge som produserte kraften vi får levert, eller nøyaktig hvor mye kraft vi vil trenge. Vi bare bruker det vi trenger og forholder oss ikke til så mye annet enn at det kommer en regning i måneden og at vi ikke har unødvendige strømbrudd. På samme måte som du slipper å forholde deg til hvilket kraftverk som genererer strømmen din, slipper du også å forholde deg til server-instanser når du bruker serverløs teknologi.
Fordelen med en serverløs arkitektur er ofte lavere kostnader ved moderat bruk, ettersom du kun betaler for de ressursene du faktisk bruker. Enten det er kjøretid for kode, lagret datamengde eller prosesserte data. Serverløs teknologi er ikke en one-size-fits-all løsning, og det finnes potensielle fallgruver og noen av dem skal jeg komme tilbake til. Nå skal vi se på hvilke byggesteiner jeg benyttet for å sette opp solkongen.cloud.
¶Hente data
Som jeg nevnte innledningsvis kan man lese data fra en inverter, og i mange tilfeller er den også koblet til internett. I mitt tilfelle har jeg en inverter fra Growatt, som har et fungerende, om enn ganske dårlig og ustabilt API. Det er fullt mulig å bruke APIet, men det er langt fra en stilstudie i hvordan man bør tilgjengeliggjøre data. Jeg hadde imidlertid ikke anledning til å være kresen her, så jeg måtte bare hente ut data etter beste evne og putte dem et egnet sted.
AWS har flere alternativer for kjøring av serverløs kode. Jeg valgte å bruke AWS Lambda, som var enklest og mest kostnadseffektivt for mitt behov. En Lambda-funksjon er en kortlevd tjeneste som kan trigges av ulike hendelser, som en melding på en kø eller en ny fil i en mappe. Levetiden er begrenset; hos AWS har en Lambda-funksjon en standard timeout på tre sekunder, og absolutt maks er 15 minutter. Betalingen baseres på faktisk kjøretid og minnebruk, noe som har gjort det svært kostnadseffektivt i mitt tilfelle.
Valg av programmeringsspråk avhenger av flere faktorer, som tilgjengelige biblioteker og personlig kompetanse. Jeg valgte JavaScript fordi det finnes et bibliotek for å kommunisere med Growatt sitt API. Selv om JavaScript ikke er det raskeste språket i en Lambda-kontekst, var hastighet ikke en avgjørende faktor for denne delen av applikasjonen.
¶Tidsseriedatabase
Som tidligere nevnt, hadde jeg behov for et sted å lagre data. Dette skyldes tre hovedårsaker:
- For å unngå at besøkende på nettstedet overbelaster Growatt’s API.
- Growatt’s API er ofte utilgjengelig.
- APIet gir kun tilgang til data fra de siste timene, mens jeg ønsker data helt tilbake til anleggets installasjon i november i fjor.
Derfor bruker jeg en AWS Lambda-funksjon til å hente og lagre data i AWS Timestream, en tidsseriedatabase designet for IoT-enheter. Denne databasen er tidssentrert og tilbyr fleksibel konfigurasjon. For eksempel kan nyere data som benyttes mye oppbevares i hurtigminne, mens eldre data flyttes til disk. Databasen er også skjemaløs og støtter SQL, noe som forenkler datahenting. Den har dessuten mange innebygde funksjoner for tidsbasert databehandling.
Timestream er en serverløs tjeneste som eliminerer behovet for å sette opp en databaseserver. Jeg oppretter bare en database og angir tabeller med litt konfigurasjon. Databasen skalerer automatisk med datamengdene, noe som betyr at den kan håndtere økende last uten nevneverdig manuell inngripen. Jeg betaler kun for antall lese- og skriveoperasjoner, noe som gjør det kostnadseffektivt.
¶EventBridge Scheduler
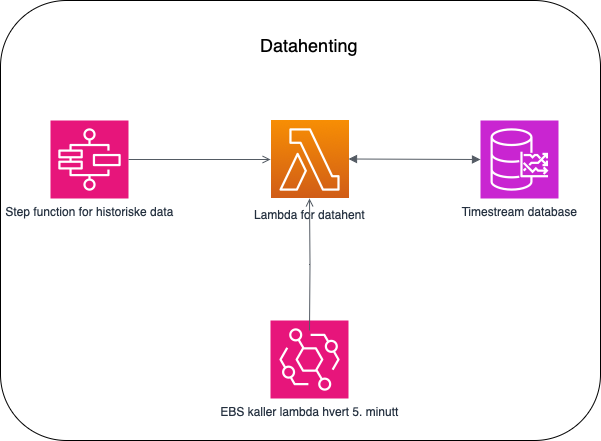
EventBridge Scheduler (EBS) hos AWS er i bunn og grunn en tjeneste for å kjøre Cron-jobber. Det lar deg utløse handlinger, som å kalle en Lambda-funksjon, på bestemte tidspunkter eller intervaller. I mitt tilfelle brukte jeg EBS til å aktivere den tidligere nevnte Lambda-funksjonen hvert femte minutt for å hente nye data fra inverteren.
¶Step Functions for historiske data
Jeg har allerede en Lambda-funksjon for å hente realtidsdata, og ønsket å gjenbruke den for å samle data helt fra anleggets oppstart. Løsningen jeg benyttet kalles Step Functions, og fungerer som en tilstandsmaskin. Den lar meg organisere dataflyten ved hjelp av byggeklosser.
I dette tilfellet bruker jeg den samme Lambda-funksjonen som før, men med spesifikke inputparametere for å angi hvilket tidsvindu jeg vil hente data for. Funksjonen “sover” i noen sekunder mellom hvert kall for å unngå blokkering fra Growatt’s API. Med Step Functions kan jeg spesifisere tidsperioden jeg ønsker data fra og systematisk hente alle dataene, inntil alt er samlet og lagret i Timestream. Dette er en engangsoperasjon, men muliggjør gjenbruk av Lambda-funksjonen med minimalt med ekstra arbeid.
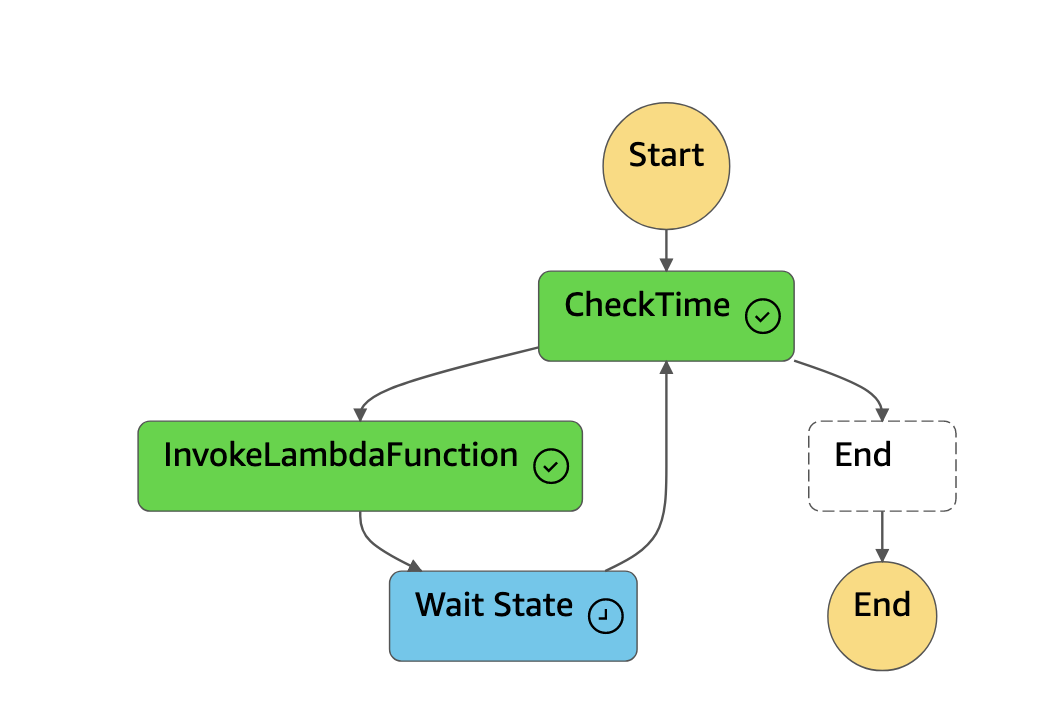
Det er verdt å merke seg at Step Functions kan bli kostbart ved hyppig bruk. Det eliminerer heller ikke behovet for kode, men tilbyr en visuell måte å strukturere og overvåke dataflyten. Hver tilstand i maskinen sender ut et resultat som neste tilstand bruker, og du kan følge kjøringen i sanntid.
Under finner du byggeklossene jeg benyttet for å hente nye og gamle data. Som figuren indikerer benyttes en og samme lambda med ulike inputparametere
¶Eksponering av data via API
Etter å ha opprettet en database og satt opp mekanismer for kontinuerlig datainnsamling, er det neste naturlige steget å tilby et API for å tilgjengeliggjøre denne informasjonen. Til dette formålet har jeg benyttet en AWS Lambda-funksjon. Denne funksjonen er designet for å trekke ut data for en bestemt dato. Standardinnstillingen er dagens dato, men det kan også angis manuelt. Det er viktig å merke seg at en Lambda-funksjon i seg selv ikke uten videre er tilgjengelig på internett. Derfor har jeg brukt en API Gateway foran Lambda-funksjonen. Denne gatewayen eksponerer Lambda-funksjonen på en spesifikk URL, slik at brukere kan spesifisere en dato og dermed hente ut relevante data. Med dette oppsettet har vi effektivt gjort dataene tilgjengelige via et API-endepunkt.
Når det gjelder valg av programmeringsspråk for Lambda, er det noen viktige hensyn å ta. Når brukere aksesserer API-et, vil de i praksis vente på data som returneres i en synkron operasjon. Derfor er responstid en kritisk faktor. Alle Lambda-funksjoner vil oppleve en “kaldstart” - en initialiseringsfase som potensielt kan forsinke datatilgangen. Dette er spesielt relevant for programmeringsspråk som Java og .NET, som er optimalisert for langtidskjørende prosesser, ikke nødvendigvis for rask oppstart. Det er mulig å kompilere til native også for disse språkene, men det krever ofte lengre byggetid. Programmeringsspråk som Rust og Go er mer egnet for Lambda-funksjoner som krever rask oppstart. Dette gir også den ekstra fordelen av å redusere den fakturerbare tiden for Lambda-bruk.
¶Et nettsted blir til
Selv om fokuset i denne bloggposten hovedsakelig er på serverløse teknologier, er det verdt å nevne at frontenden er utviklet med React og TypeScript. Når jeg gjør endringer og er klar for produksjonsutrulling, trenger jeg en plass for å gjøre disse filene tilgjengelige på nettet. Dette fører oss til en annen AWS-tjeneste: S3 (Simple Storage Service).
S3 er et skybasert filsystem og var blant de første tjenestene AWS lanserte, helt tilbake i 2006. Det frigjør oss fra behovet for å administrere egne filservere ved å tilby lagringsløsninger i skyen. Ikke bare det, men S3 gir også muligheten for å gjøre filer offentlig tilgjengelige.
I mitt tilfelle har jeg brukt S3 til nøyaktig dette formålet. Jeg har lastet opp de komprimerte filene til en S3-bøtte og gjort dem tilgjengelige via en unik URL. Dette gir meg en enkel og effektiv måte å dele min frontend på nettet.
Det er imidlertid fremdeles noen problemer her, for når jeg sier “på en URL” så er dette snakk om en ganske kryptisk generert URL som de aller fleste aldri vil huske, og enda mindre en URL jeg ønsker å dele med andre. Jeg ønsker jo å ha dette på et eget domene! Vel la oss se hva som skal til for å få til dette.
Før vi går videre, må vi snakke litt om CloudFront, en annen tjeneste fra AWS. Selv om jeg har erfaring med Content Delivery Networks (CDN) fra tidligere prosjekter, er dette første gang jeg benytter AWS CloudFront. Og ja, det kan virke som å skyte spurv med kanon i dette tilfellet. Men det flotte med sideprosjekter er at de gir deg muligheten til å utforske nye verktøy og teknologier. Jeg har ofte sett at det man lærer gjennom sideprosjekter, har vært direkte anvendelige også på jobb i senere prosjekt. CloudFront er en CDN som optimaliserer levering av webinnhold ved å distribuere det til flere geografiske lokasjoner. Dette forkorter lastetiden for brukere, noe som jo er et pluss. Så kan jeg jo stolt erklære at nettstedet er raskt tilgjengelig fra ulike deler av verden. I tillegg gir CloudFront et ekstra lag med DDoS-beskyttelse, noe som gir en ekstra stjerne i boka.
Det neste jeg ønsket meg var et domene, og solkongen.cloud virket som et morsomt domene for å henspeile på at her er det mye sol og mye sky. Det var også tilbud på Domeneshop på alle .cloud domener, noe man ikke skal undervurdere i tider der strømprisen tidvis er negativ. Oppsett av DNS har jeg også konfigurert via Domeneshop.
Til slutt måtte jeg selvsagt implementere HTTPS på nettstedet. I 2023 ville det være utenkelig å ha et nettsted uten kryptert trafikk, spesielt hvis jeg ønsket å unngå nedsabling fra mine kollegaer. For dette formålet har jeg benyttet AWS Certificate Manager, som tillater enkel utstedelse av sikkerhetssertifikater. Selv om prosessen var litt frustrende siden jeg gjorde diverse feilkonfigurasjoner underveis, fungerte alt etter noen forsøk. Så var trafikken kryptert og tilgjengelig for hele verden.
 Her ser du en overordnet skisse der klienter først henter nettsiden, og videre data fra backend
Her ser du en overordnet skisse der klienter først henter nettsiden, og videre data fra backend
Sol-dataene er nå tilgjengelige for alle i nesten sanntid. Mer funksjonalitet er underveis; en god historikkfunksjon står høyt på to-do-listen, i tillegg til integrering av værprognoser og estimering av strømproduksjon basert på vær og årstid. Dette gir meg også en gyllen mulighet til å eksperimentere ytterligere med maskinlæring. På lengre sikt planlegger jeg å inkludere andre data knyttet til husets totale strømforbruk og salg av overskuddsenergi. Mulighetene er mange, og jeg er åpen for gode forslag som kan videreutvikle prosjektet.
