Nå og da må vi utviklere velge mellom flere tekniske alternativ for å utvikle systemer vi jobber på. Oftest handler det om å velge hvilket bibliotek som passer best, hvordan vi skal lagre ting i databasen, eller kanskje hvilket frontend-rammeverk vi skal bruke. Og en sjelden gang kan det hende at vi må evaluere to forskjellige algoritmer eller datastrukturer.
Om alternativene har funksjonaliteten vi trenger, er det typisk tid- og minnebruk vi ser på. Minnebruk er noenlunde greit å måle, men det å måle tidsbruk korrekt er vanskelige greier. Derfor prøver vi som regel å ta et par snarveier, og ser gjerne på kjøretidskompleksiteten for å få et greit estimat.
For eksempel kan det hende at vi ser på to datastrukturer, der en bruker O(n) tid på en operasjon og en annen bruker O(n log n). I “gamle dager” kunne man si at den første antakeligvis var det mer fornuftige valget for store datasett, men med dagens maskiner er ikke det nødvendigvis lenger sant. Det kan faktisk hende at datastrukturen som bruker O(n log n) tid alltid er bedre!
Men hvorfor? Hva har skjedd som gjør at kjøretidskompleksiteten ikke er like relevant, og kan vi fikse det på en eller annen måte?
¶Ting var enklere på 80-tallet
I 1980 var CPU- og minnehastigheten i en datamaskin relativt lik. En CPU-operasjon kunne være litt raskere, men ikke så mye at folk trengte å tenke på det. Siden den tid har ting endret seg drastisk, og prosessorhastigheten er nå milevis foran tiden det tar å lese data fra minne:
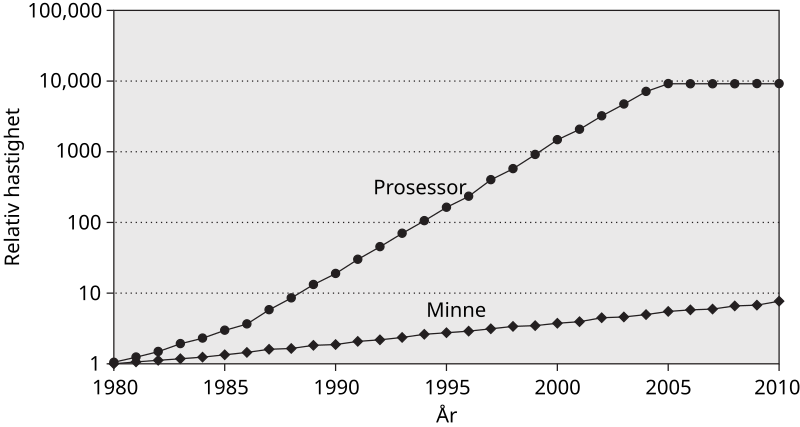
Konsekvensen av dette er at noen antakelser man bruker for å regne på kjøretid nå er helt på jordet. Som regel, selv i dag, bruker man den såkalte RAM-modellen for å estimere hvor lang tid en algoritme bruker på å kjøre. Litt forenklet antar RAM-modellen to ting:
- Enkle operasjoner (
+,*,==, osv.) tar en tidsenhet - Å lese minne tar en tidsenhet
At operasjonene ikke tar like mye tid er ikke veldig farlig, så lenge forskjellen ikke er alt for stor. Men når det å lese inn minne fra RAM tar røflig 150 klokkesykler begynner denne modellen å slå store sprekker.
Det som gjør situasjonen enda mer kinkig er innovasjonen som skjedde i 1985: Da kom Intel med i386, den første masseproduserte chippen som kunne snakke med en cache. Prosessorcacher er geniale greier: de gjør at data vi har brukt tidligere – eller er i nærheten av det vi bruker – tar mye kortere tid å lese inn. Problemet er at det blir plutselig enda mer komplisert å regne på kjøretid om vi ønsker å gjøre det korrekt.
Et alternativ er å kun fokusere på tiden det tar å lese og skrive minne når det ikke er i cache, og anta at CPU- og cachebruk er “gratis” sammenlignet med minne-I/O. Det gjør fagartikkelen “The Input/Output Complexity of Sorting and Related Problems” fra 1988, hvor de definerer en modell som kalles for I/O-modellen. Modellen antar at du har to minnetyper: Internminne og eksternminne.
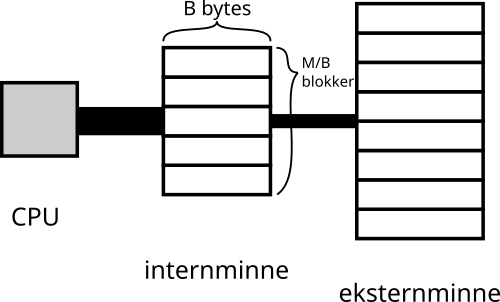
Internminne er veldig raskt å slå opp i og har lite plass (kun M bytes), mens eksternminne er tregt å slå opp i og har mye plass. I denne modellen antar man at det er gratis å jobbe med ting i internminnet, og hvis du ønsker å jobbe på eksternminnet må du manuelt skrive ting fra internminnet til eksternminnet eller visa versa.
For å være så realistisk som mulig har modellen også et konsept kalt “blokker”: Du kan ikke skrive/lese en og en byte fra eksternminne, du leser/skriver blokker med B bytes. Dette ble gjort for å representere cachelinjer, eventuelt disksektorer i harddisker.
¶Du har mer enn 1 cache
En moderne variant av I/O-modellen brukes fremdeles til å analysere disk-tunge algoritmer. Databaser og key-value stores bruker i praksis all tiden sin på å manuelt skrive og lese ting fra disk, og der passer det bra å bruke denne. Men for algoritmer og datastrukturer som kun ligger i minne blir I/O-modellen i praksis ikke brukt. Det er to store grunner til det:
For det første er det å overføre data inn og ut av cachen ikke en manuell greie, det skjer automatisk for oss utviklere nå i dag. Følgelig har vi ikke 100% kontroll over når ting går inn og ut av cachen, og vi må forholde oss til det.
Den andre grunnen er det at I/O-modellen antar at vi bare har to nivåer i minnehierarkiet, men det er ikke tilfelle: Prosessorer har jo helt siden 50-tallet også hatt prosessorregistre. Ikke nok med det, etter at den første integrerte cachen dukket opp i en prosessor, har vi bare stappa fler og fler inn sammen med den. Akkurat nå er vi oppe i 3 cacher på prosessorbrikken (kjent som L1, L2 og L3), så en representativ modell bør jo helst se slik ut:
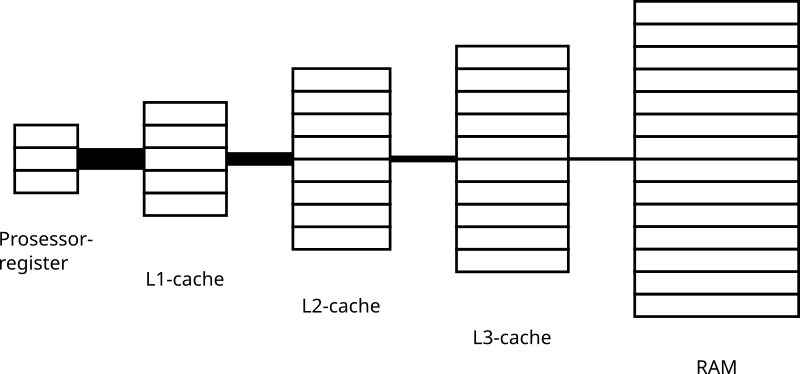
Problemet er at alle disse cachene har forskjellig båndbredde, størrelse, og av og til forskjellig lengde på cachelinjene. Å prøve å modellere dette blir bare kaos, og jeg aner ikke hvordan man ville lagd algoritmer optimalisert for en slik modell. Det virker såpass knotete at jeg ikke ville vært overrasket om forskere bare hadde gitt opp med å modellere minne på en mer korrekt måte.
Den gang ei. Noen smartinger bestemte seg nemlig for å snu problemet på hodet: I stedet for at man optimaliserer for et spesifikt minnehierarki, hva om man “bare” optimaliserer for alle forskjellige minnehierarkier?
¶Optimaliser for alt!
Det er nettopp det man gjør i fagartikkelen “Cache-Oblivious Algorithms” fra 1999. De har i praksis samme modell som I/O-modellen, men sier at du ikke har full kontroll på når blokkene flyttes mellom intern- og eksternminnet. I tillegg får du ikke vite størrelsen på cachelinjene (B) eller hvor mye minne du har i cachen (M), så du må rett og slett optimalisere for alle varianter.
Det kule er det at når du optimaliserer på en slik måte for to nivåer, gjør du det også for alle minnehierarkier, uavhengig av hvor mange nivåer de har. Jeg skal ikke gå inn i detalj på hvorfor det er tilfelle, men ideen går noe sånt som dette. Om man har et minnehierarki med flere nivåer enn to, kan man splitte det opp i to:
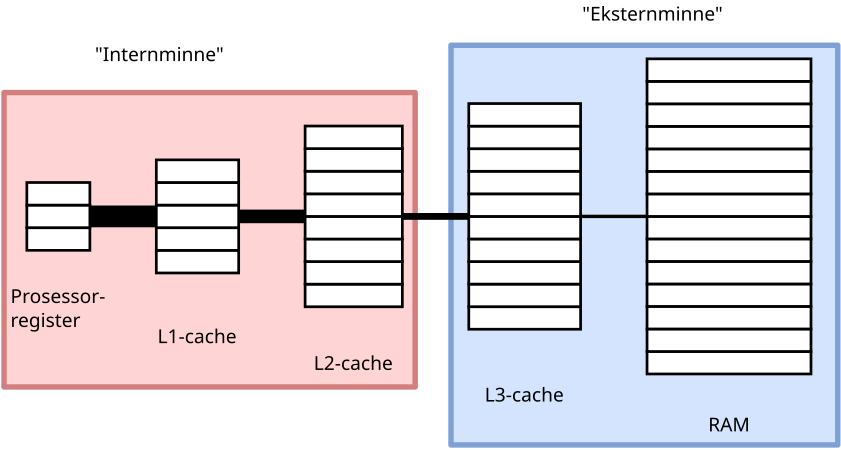
Det på den venstre siden kan sees på som internminnet, mens det på høyresiden kan sees på som eksternminnet. Om man har optimalisert for alle cache- og cachelinjestørrelser, vil også dataoverføringen være optimalisert mellom disse to delene av minnehierarkiet. Og siden vi kan dele opp minnehierarkiet hvor vi vil og alle “delinger” er optimale, så gir det mening at algoritmen er optimal for hele minnehierarkiet.
Ut fra dette lager artikkelforfatterne et par såkalte cache-uvitende algoritmer og analyserer dem. Hvorfor de bestemte seg for å kalle de cache-uvitende er et godt spørsmål, uten noe særlig godt svar…
I teorien er denne fremgangsmåten for å lage algoritmer genial. For det første gjør det at programmene dine kjører optimalt på forskjellige CPU-typer. Men du kan også føle deg trygg på at ytelsen ikke blir betraktelig dårligere om flere prosesser kjemper om både CPU og cache: siden algoritmen er optimal selv om du halverer cachestørrelsen, vet du at den også vil kjøre greit samtidig som en annen prosess bruker f.eks. halvparten av cachen.
¶Fungerer det i praksis?
I praksis er ikke cache-uvitende algoritmer mye å skrive hjem om akkurat nå. Man har lagd varianter av sorteringsalgoritmer, B-trær, og matrisemultiplisering som er cache-uvitende, og selv om noen av dem er gode, slår ingen av dem de mest optimaliserte variantene som allerede eksisterte fra før av. Det skal sies at det er noen steder hvor de er bedre, men det er datastrukturer som sjelden brukes utenfor nisjeområder.
Og det er jo litt trist, for det hadde vært kjekt med en slags “snarvei” for å kunne måle ytelse. Sannheten er at man må fremdeles brette opp ermene og sette i gang med målinger hvis man skal finne det beste alternativet. Heldigvis er dette sjelden kost hvis man jobber med generell utvikling i disse dager, og ofte er det noen som har gjort det før.
Men jeg ønsker jo ikke at du skal gå hjem helt cache-uvitende heller! Som et plaster på såret har jeg samlet opp et par tommelfingerregler til de gangene ytelsesmålingene ikke gir deg et entydig svar:
- Å lagre flere ting sammen er bedre enn å dele de opp i flere mindre biter: B-trær er for eksempel (vanligvis) bedre enn binærtrær
- Å allokere minne er som regel en dum idé om du kan unngå det: ikke-muterbare datastrukturer er så og si alltid verre enn muterbare datastrukturer (men på bekostning av forståelse)
- Det er greit å se på kjøretidsanalyse hvis du har mye data og det er stor forskjell mellom kjøretidene: O(1) er ofte bedre enn O(n), mens f.eks. O(1) og O(log n) er såpass like at du bør gjøre noen målinger
Helt til slutt vil jeg nevne at hvis du ikke klarer å måle noen forskjell i ytelsen mellom to alternativ, så er det antakeligvis ikke så farlig hva du velger. Selv om det er interessant, så er det beste ofte å bare å velge en av dem og faktisk begynne å implementere funksjonaliteten kunden ønsker seg.
