Dette er en liten historie om hvordan EFS nærmest tok livet av Kubernetes-clusteret vårt, og hvordan du kan unngå å havne i samme knipa — selvom du ikke bruker EFS.
Høsten 2018: En kollega og jeg satt opp et Kubernetes-cluster på AWS. Vi gikk i prod uten særlig om og men, og ting fungerte som forventet. Spol frem 5-6 måneder, og situasjonen ble snudd på hodet over natta.
Våren 2019: Etter å ha kjørt uten problemer i nesten et halvt år begynte Kubernetes-custeret vårt å krangle. Vel, ihvertfall nodene. Det første symptomet vi observerte var at mange av pod-ene våre hadde kort levetid, og det var hyppige restarts. Etter at dette hadde pågått en stund fikk vi av og til en kranglete node som Kubernetes selv ikke klarte å få skikk på.
Etter å ha undersøkt logger fra appene våre, og (det vi antok var) relevante metrikker kunne vi ikke se noen åpenbar grunn til at ting skulle bli restartet. Ettersom Kubernetes fortsatt slet med å få kontroll på enkelte noder ble vi ved flere anledninger tvunget til å rett og slett gå i EC2-konsollet og “fysisk” skru av enkelte noder. Kubernetes fikk opp en ny node, som etter kort tid gikk i lås på nytt. Vi hadde et dypere problem.
Litt graving viste at det utløsende symptomet var at pods etter kort tid begynte å bruke uvanlig lang tid på å svare på helsesjekken sin. Dette fikk Kubernetes til å bestemme seg for å ta pods ned og så opp igjen. Dette utspilte seg om og om igjen, og etter nok slike runddanser sluttet noden å reagere på masternes instrukser. Hva i all verden var det som foregikk?
¶Disk?
En dag satt jeg for nte gang og kikket på output fra kubectl get pods, med en
tåre i øynene, da det slo meg — alle pod-ene som hadde problemer brukte disk fra
EFS. Mange av systemene vi kjører i dette clusteret har noen år på baken og
bruker disk. Som en del av migreringen til Kubernetes kom vi frem til at EFS
ville være bra nok for denne disktilgangen (som stort sett besto av
config-filer). Det viste seg å bare nesten være sant.
AWS selger EFS med blant annet denne teksten:
Throughput and IOPS scale as a file system grows and can burst to higher throughput levels for short periods of time to support the unpredictable performance needs of file workloads. For the most demanding workloads, Amazon EFS can support performance over 10 GB/sec and up to 500,000 IOPS.
Dette høres jo lovende ut. Men, hva mer sier AWS om throughput?
Amazon EFS Bursting Throughput (Default)
In the default Bursting Throughput mode, there are no charges for bandwidth or requests and you get a baseline rate of 50 KB/s per GB of throughput included with the price of storage.
Vår bruk av EFS bestod først og fremst i å lese noen config-filer. Veldig lite skriving. Datamengdene våre var dermed på godt under 1GB. Altså var vi garantert hele 0.05 Mbit/s i overføring.
Når vi så visste at samtlige pods som hadde problemer brukte samme EFS share, og overføringen fra EFS sammenlagt var strupet til 0.05 Mbit/s var det ganske åpenbart hvor problemet lå. Men hvorfor tok det 6 måneder før dette ble et problem?
¶AWS bustable ressurser og credits
Mange AWS-tjenester er såkalt “burstable”. Altså har de en eller annen baseline performance som man kan overgå i en gitt tidsperiode hver dag. Dette systemet baserer seg på credits - så lenge du holder deg under burst-grensa tjener du credits per time, og når du går over så bruker du av denne credit-balansen.
EFS har burstable throughput, som forklart i dedikert dokumentasjon. En umiddelbar utfordring her er at AWS antar at behovet for throughput skalerer lineært med mengden data du lagrer på EFS. For data som er “read mostly” passer dette ikke veldig godt. Men fortsatt kan man spørre seg - hvorfor tok det 6 måneder før vi fikk problemer med dette?
Det konkrete problemet vi løp inn i er så vanlig at AWS har en egen FAQ-side dedikert til det: Hva er greia med EFS burst credits? EFS tillater at man sparer opp 2.1TB med burst-trafikk per TB man har på et share, minimum 2.1TB. Når du oppretter et nytt share starter du med full credit-balanse.
Sånn så problemet ut for oss:
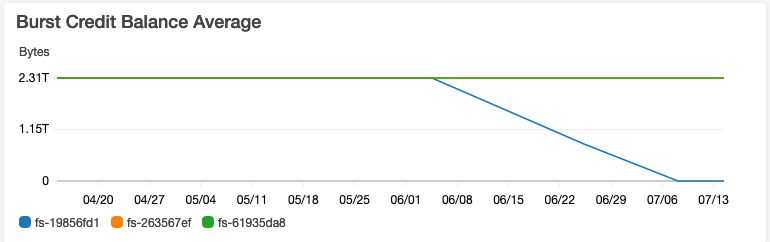
Altså:
- Vi opprettet et EFS share for en håndfull config- og logg-filer for eldre tjenester som stort sett leses, over 0.05 Mbit/s.
- Vi startet med en credit-balanse på 2.1TB.
- Ettersom lese-behovet vårt bare ligger litt over default throughput tok det et halvt år før vi hadde brukt opp creditsene våre.
- Når creditsene var borte fikk Pods strupet I/O idet de skulle lese fra EFS.
Dermed feilet en del pods helsesjekkene sine, og ble restartet av Kubernetes, om og om igjen. Dette forsterket problemet, da en del av tjenestene leste en del data fra disk under oppstart. D’OH!
¶Hva skal vi lære av dette?
Så hva skal du, kjære leser, ta med deg fra denne lille anekdoten? Vi lærte opptil flere ting fra denne tabben:
- Les bruksanvisningen
- AWS sitt burstable/credits-system brukes på mange tjenester, forstå hvilke, hvordan det gjelder, og ikke minst følge med på credit-balansen der det er aktuelt
- AWS scale er muligens magnituder over din egen scale
- Å vurdere risikoen med en gitt AWS-tjeneste er ikke-trivielt
(Vi kan allerede “unngå disk i skyløsninger”, men all programvare er ikke til all tid i en idéell tilstand).
Når det oppsummeres som her så fremstår det kanskje idiotisk av oss å ikke orientere seg om hvordan en tjeneste fungerer før vi tar den i bruk. Dette er nok velrettet kritikk, men gitt den mengden med eksterne tjenester og biblioteker vi tar i bruk hver eneste dag er det nok utopisk å innbille seg at vi skal ha 100% oversikt over alle detaljer for hver av dem. Mitt håp med dette innlegget er at du er hakket mer nøye neste gang du ser over vilkårene for et sky-produkt du ikke har brukt før.
Uavhengig av at vi ikke kjente til dette systemet reagerer du kanskje på at vi ikke oppdaget det via metrikker eller alarmer? Vi har rikelig med AWS-metrikker i Datadog, men vi har tydeligvis så mange at vi ikke klarer å følge aktivt med på alle sammen. I tillegg er alarmene våre fortsatt manuelt definert, heller enn å rapportere om generelle avvik - “NB! EFS Credits synker bratt”. Dette er utfordringer vi kan løse i ettertid, men vi sitter sikkert med ytterligere slike skylapper som vi enda ikke kjenner.
¶AWS Gratis-tier-fellen
Det er fristende å kalle denne feilen et tilfelle av “AWS free tier-fellen”, en felle som manifisteres seg på én av to måter. Den ene er at ting slutter å fungere, som i vårt tilfelle. Den andre er at driftskostnadene dine plutselig skyter i været. Ingen av dem er spesielt morsomme, men begge er dessverre nokså vanlige. Hvordan skal du unngå dem? Lese vilkår, og følge med på AWS sine egne metrikker, særlig credits-balanse, der det er aktuelt. Og ved å krysse fingerne for at du klarer å følge med på alt.
