Den første tingen jeg leter etter når jeg skal lære meg et nytt programmeringsspråk, er immutable og persistente datastrukturer. Dette er en yrkesskade jeg har fått fra Clojure. Jeg har en tendens til å strukturere hele systemet mitt rundt disse datastrukturene. De er smarte, kjappe, effektive, immutable og fremragende.
I denne bloggposten skal jeg gi deg den samme skavanken.
¶Aksiom: Immutability er bra
Dette skal jeg ikke prøve å selge, fordi det er et vanskelig salg.
Som i, jeg kjenner noen som ikke er spesielt begeistret for immutable verdier, og jeg aner ikke hvordan jeg skal selge det til dem.
Immutability vil fundamentalt eliminere hele kategorier med bugs fra koden din. Det gir deg helt nye modelleringsmuligheter, som å gjøre en “hva hvis”-operasjon på dataene dine uten å være redd for at du ødelegger tilstanden din.
Men, hvis jeg sier dette til noen som ikke liker immutability, er svaret stort sett en variant av: “jeg har ikke det problemet”. Uten at jeg forstår hvordan det kan ha seg. Men sånn er det visst bare.
¶Problemet med immutable verdier er at de er immutable
La oss si at du har et immutable hash map eller noe sånt. Den er typisk implementert ved hjelp av en eller annen trestruktur under panseret, som er helt vanlig for mange ulike typer datastrukturer.
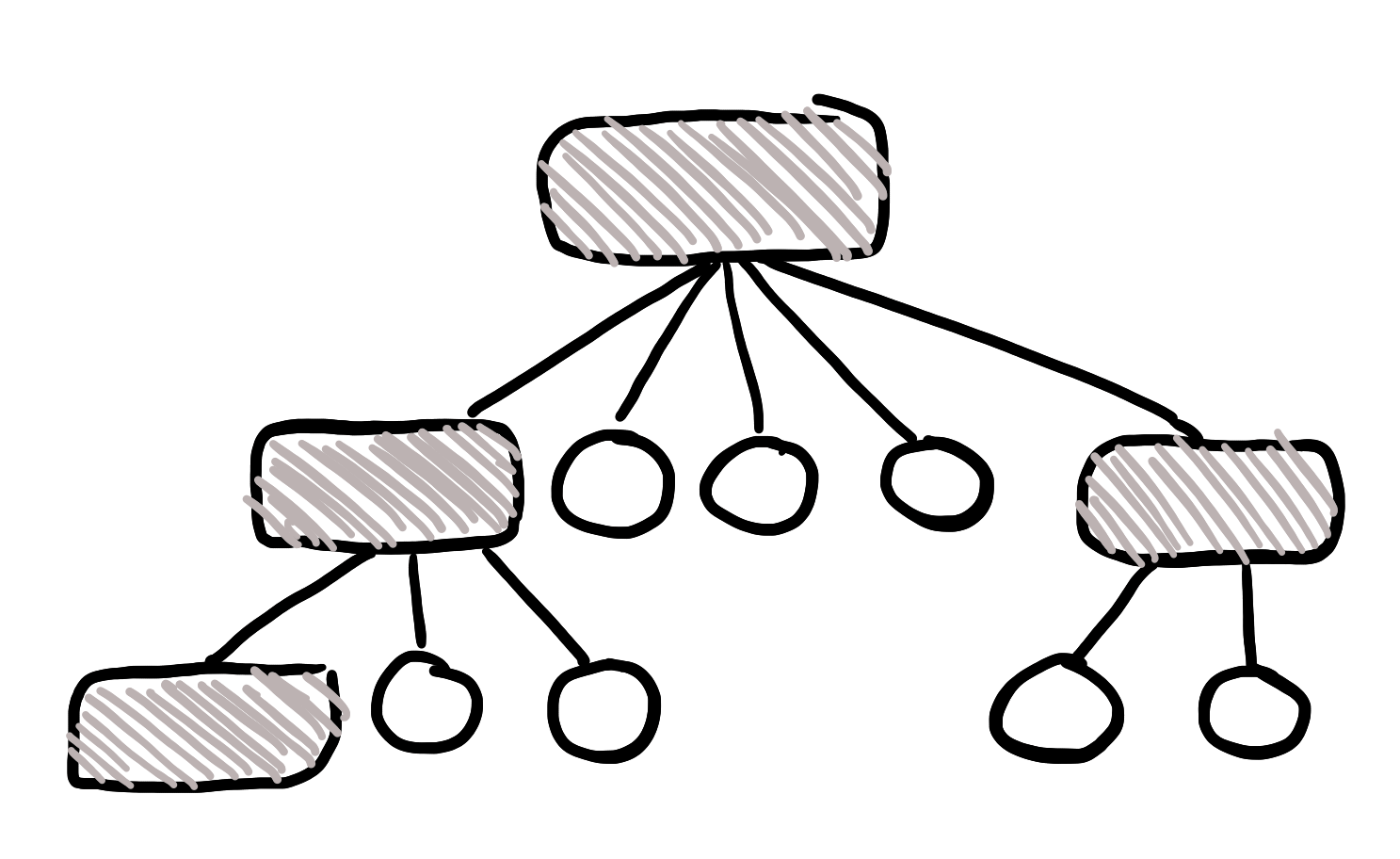
Problemet her oppstår når vi har lyst til å legge til en nøkkel i map-et. Dataene er immutable, så vi kan ikke endre på datastrukturen!
Det betyr at vi er nødt til å lage en fullstendig kopi av alle dataene, og legge til de nye greiene i denne kopien.
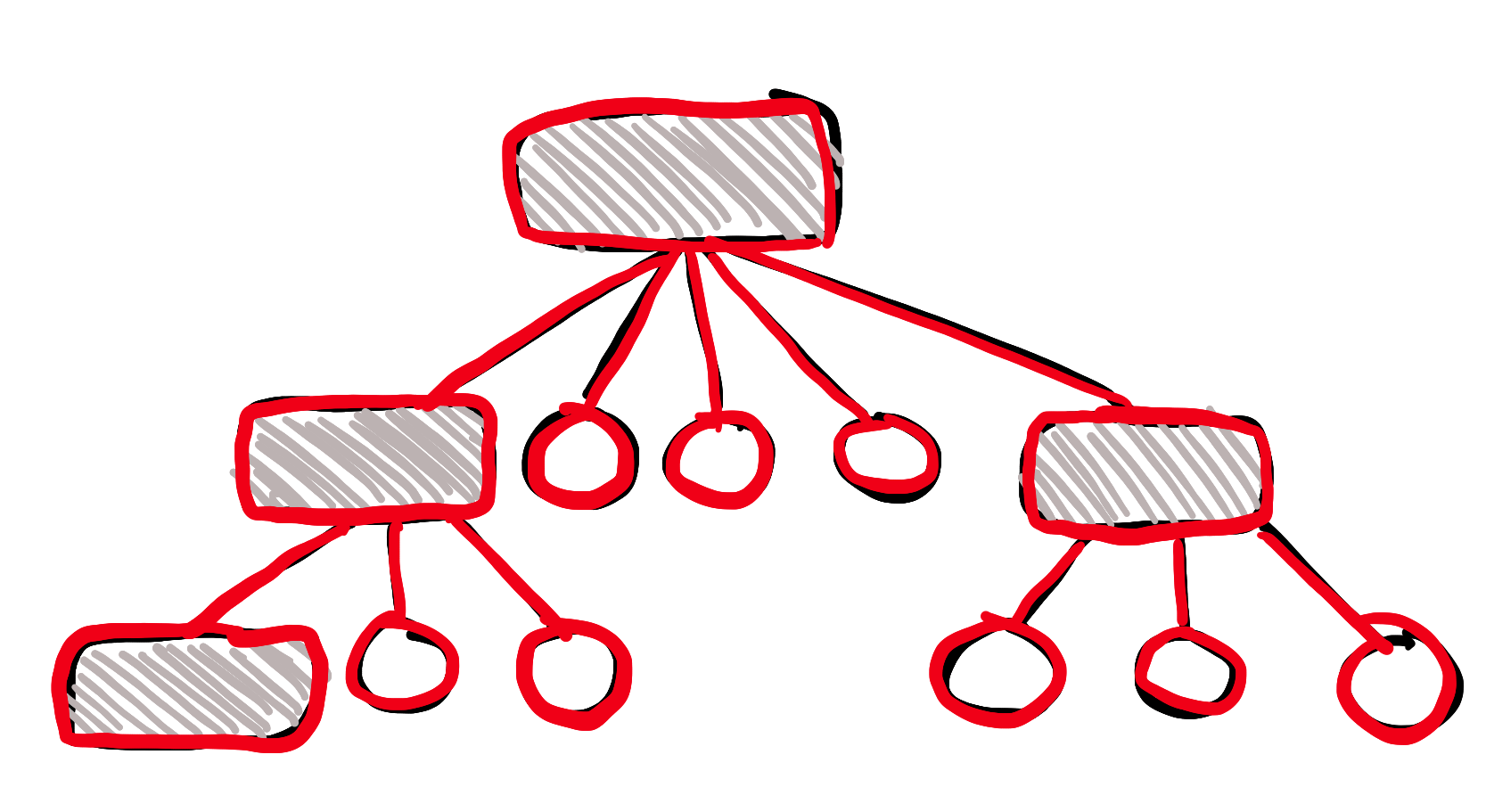
(Rødt = nye greier)
Hvis du sammenlikner med bildet over, ser du at nede til høyre har vi en ny node i treet. Og vi var pent nødt til å kopiere alle dataene i trestrukturen.
Vi kan jo ikke gjøre noen endringer på den immutable originalen!
Dett var dett, da? Immutability suger, siden du er nødt til å kopiere alt sammen hver gang du vil endre den minste ting?
Jepp.
Samtidig, nei.
¶Copy on write - njaaaa
Altså, jeg skal ikke rakke helt ned på copy on write (CoW). Det finnes noe software her og der som kanskje er nevneverdig som bruker CoW på en noenlunde brukandes måte, som Linux-kernelen.
Ett av de sentrale prinsippene i Linux/Unix lener seg på CoW - nemlig forking. Eller gaffel, som Torstein Bae liker å si. Når du har en prosess som bruker 11 GB RAM, og du forker prosessen, har du en helt ny prosess som er identisk til den du forket ut av, med sin egen kopi av de 11 GB-ene med RAM. For å unngå at det å forke skal være så treigt at selv den mest rudimentære hjemmelagde ML-modellen begynne å gråte, bruker kernelen CoW. Det å forke en prosess utfører faktisk ikke en svær kopi-operasjon på minnet. Det er bare når den forkede prosessen begynner å skrive til minnet at kernelen begynner å kopiere først og så skrive - altså copy on write.
CoW er teknisk sett en type persistent datastruktur.
Men, CoW er best når dataene er mutable. Når dataene dine er immutable hele vegen igjennom, har du et annet valg.
¶Structural sharing - jepp jepp jepp
Dette er det jeg kaller en persistent datastruktur.
Ok.
Vi har en svær datastruktur. Vi vet at den er immutable. Vi ønsker å endre en liten del av den. Hvilken optimalisering kan vi gjøre her?
Ser du det enda?
Den gamle datastrukturen er immutable. Så vi kan bare gjenbruke den!
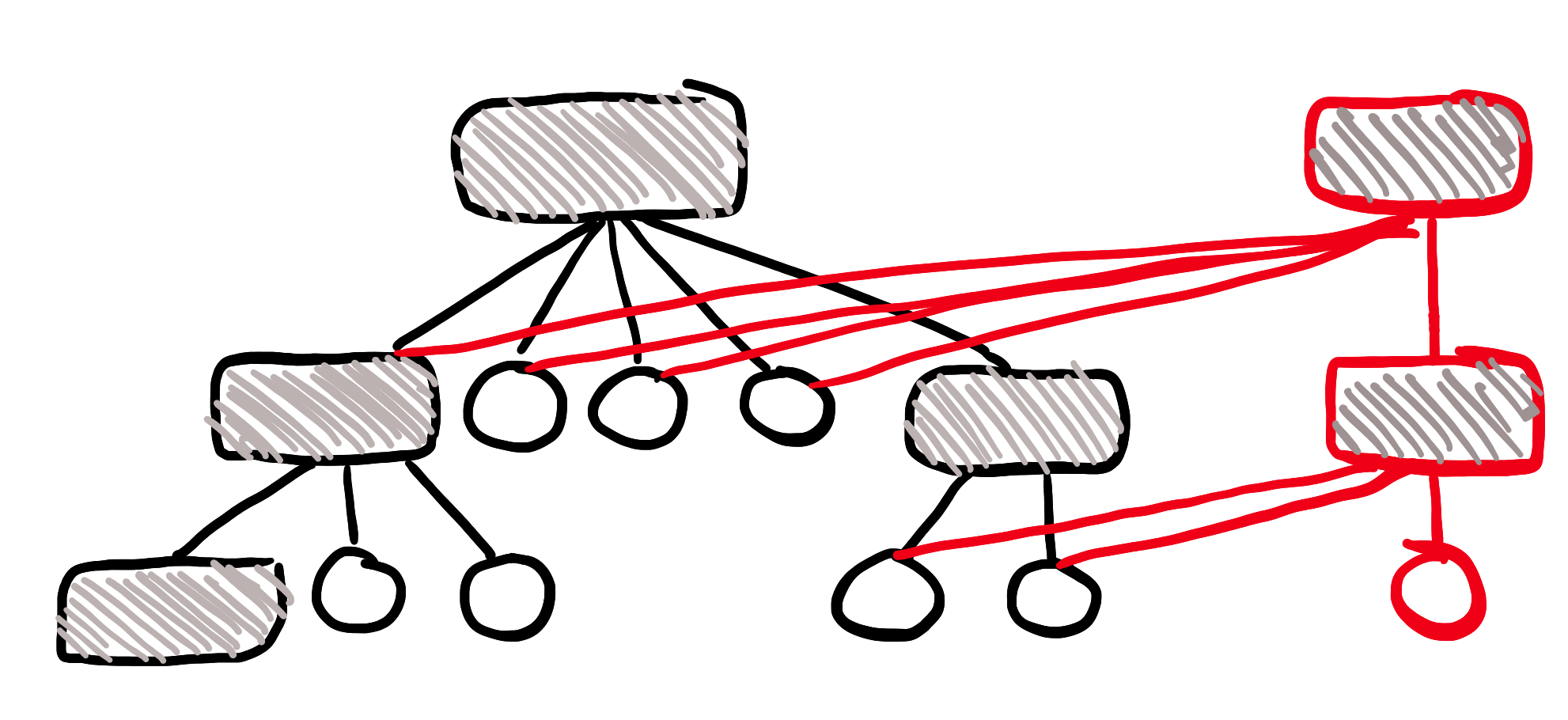
(Rødt = nye greier)
Ser du hva som skjedde?
Hvorfor ta en kopi av immutable data?!
Alt vi trenger å gjøre er å lage en ny rot-node, en ny node etter den og en ny data-node, og så kan vi bare peke på all den gamle dataen. Husk, den gamle datastrukturen er immutable, når alt kommer til alt. Så hele ideen her er at den aldri vil endre seg.
Og med det forstod du Clojure sin state-modell. Selve verdiene er alltid immutable. Du kan lage funksjoner som tar imot en immutable verdi, som returnerer en oppdatert immutable verdi. Å lage nye immutable verdier er billig - fordi du kan dele nesten alle dataene i den nye datastrukturen med den gamle.
Yay!
¶Clojure gjør også en annen skikkelig stilig greie
I den virkelige verden (noen av oss ser ut til å leve i en slik), viser det seg at hvis du bare har et lite map med en håndfull keys i seg, er det litt vel dyrt å jobbe på disse faaaaancy trestrukturene.
Under panseret gjør Clojure en stilig optimalisering: hvis mappet ditt har færre enn 8 (tror jeg..) elementer i seg, vil det bare bli representert som en helt vanlig muterbar liste/array!
Når du legger til et element i mappet, vil Clojure gjøre en full kopi av lista, med de gamle elementene og de nye.
Hvorfor er det kult?
Vel, det viser seg at det faktisk er kjappere i praksis å gjøre det på den måten, når du jobber med ganske lite data. Å sjekke en liste med 8 elementer etter hvorvidt en key eksisterer i den eller ikke, er mye kjappere enn å vedlikeholde og balansere et binært tre.
Tenk på det som generasjoner i garbage collection. Under panseret, er dataene dine i “eden” space eller “tenured” space. Som er fancy ord for: data som nettopp ble laget og som ble kastet bort med en gang, garbage collectes annerledes enn langtlevende data. Dette skjer fullstendig under panseret, som en ytelsesoptimalisering, uten at du må knote for å få det til å funke.
¶Enda en stilig greie
La oss si at du har en sånn typisk funksjon som er en tight loop som legger på 100-vis av greier på et map, basert på en data stream eller noe sånt. En CSV-fil eller en database eller noe parsing eller noe sånt.
I utgangspunktet er alle maps immutable, så det betyr at du må gjøre hundrevis av potensielt dyre operasjoner på persistente datastrukturer.
Men! Clojure har noe de kaller for “transients”.
Transients er en lik men annerledes versjon av immutable datastrukturer. Først “låser du opp” datastrukturen din og lager et “transient” map (eller liste, eller set, eller…)
Her er den vanlige, immutable versjonen.
(->> [1 2 3 4]
(reduce
(fn [res curr] (conj res (+ 1 curr)))
[]))
;; [2 3 4 5]
Her har du samme kode, med transients. Som du ser, er eneste endringen at vi sier at lista vår er “transient”, og at vi må bruke en spesiell versjon av conj som slutter med et utropstegn.
(->> [1 2 3 4]
(reduce
(fn [res curr] (conj! res (+ 1 curr)))
(transient [])))
;; clojure.lang.PersistentVector$TransientVector@139e6e1d
Heisann! Vi glemte å gjøre den persistent til slutt.
(->> [1 2 3 4]
(reduce
(fn [res curr] (conj! res (+ 1 curr)))
(transient []))
persistent!)
;; [2 3 4 5]
Denne optimaliseringen gjør at Clojure vet at i loopen vår, vil ingen andre bruke datastrukturen, så den kan være mange hakk mindre fancy under panseret i måten den bygger opp datastrukturen. Og potensielt mye kjappere, siden den slipper overheadet med å vedlikeholde en persistent datastruktur.
Clojure har ganske fete datastrukturer.
