Indeksering er den aller viktigste måten vi kan sikre god ytelse fra en SQL-database på. Det er ikke så mye en utvikler trenger å vite om hvordan databasen fungerer, men å lage gode indekser er en utviklers oppgave. For å kunne lage gode indekser må man vite hvilke databehov applikasjonen har og hvordan den spør etter data. Derfor er utvikleren bedre rustet til å lage gode indekser enn en DBA som kun ser på databasen og datamodellen.
¶Hva er en indeks?
Konseptuelt så fungerer en indeks i en SQL-database på samme måte som en indeks i en bok. Den er lagret separat fra selve tabellen og tar opp plass på samme måte som en indeks bakerst i en bok har sine egne sider. Indeksen er sortert slik at det skal være raskt å slå opp og den kan gjerne inneholde flere felter som f.eks en telefonkatalog som er sortert først på etternavn og deretter fornavn. Til slutt har hvert innslag i indeksen en peker til hvor den faktiske raden i tabellen er lagret. Akkurat som sidetallet i indeksen bakerst i boka.
Når vi bruker ordet indeks i forbindelse med SQL så mener vi en indeks av typen B-tree. Det finnes flere typer indekser, men dette er den viktigste. B-tree står for balanced tree (ikke binary tree). En B-tree-indeks er litt mer komplisert enn en indeks i en bok fordi den må kunne oppdateres hver gang dataene i tabellen endrer seg. Derfor består indeksen av to komponenter:
- En sortert dobbeltlenket liste (indeksens løvnoder)
- Et søketre (B-tree)
Løvnodene
Indeksen må være sortert. Derfor kan vi ikke lagre indeksen sekvensielt fordi det vil innebære at vi må flytte dataene hver gang det skjer en endring i tabellen - og det blir for kostbart. Indeksen er derfor representert som en dobbeltlenket liste som har en logisk rekkefølge som er uavhengig av hvordan den er lagret. Hver node i indeksen har en lenke til både det foregående og det neste elementet. Som en java.util.LinkedList. Flere innslag i indekser er gruppert sammen i blokker som er databasens minste lagringsenhet.
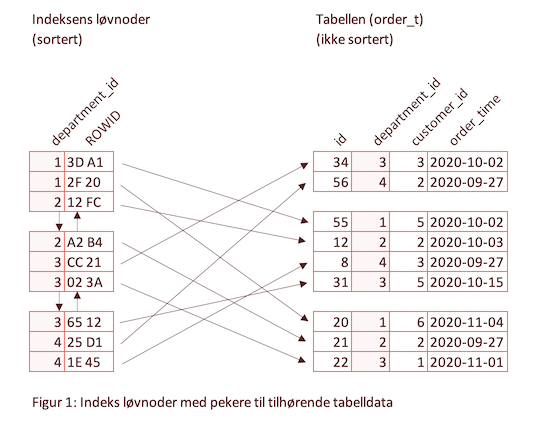
Figur 1 viser et utdrag fra en indeks på kolonnen department_id i tabellen order_t (suffix _t fordi order er et reservert ord i SQL). Hvert innslag i indeksen inneholder den indekserte verdien og en ID som peker til raden i den faktiske tabellen.
Søketreet (B-tree)
Kort fortalt er det trestrukturen i en indeks som gjør at oppslag er raskt. Hvert innslag i de indre gren-nodene (altså de som ikke er løvnoder) består av den største verdien fra den respektive løvnoden. En gren-node inneholder verdiene til flere løvnoder og disse er også sortert på samme måte. Treet består av nok gren-noder på det første nivået til at alle løvnodene er dekket. Det neste nivået i treet bygges opp på samme måte ved at hver node inneholder de største verdiene fra hver node i det foregående nivået helt til alle innslagene får plass i én enkelt node: rotnoden.
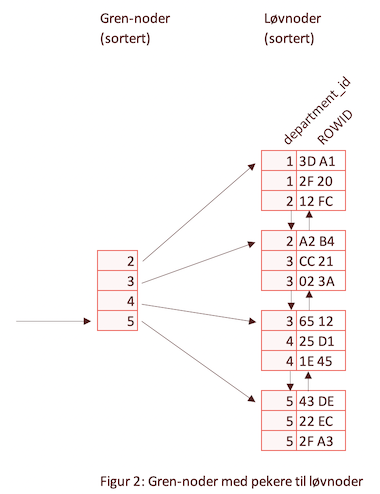
Figur 2 viser hvordan gren-nodene består av de største verdiene fra hver node i det neste nivået i treet. Treet er balansert slik at det alltid er like mange nivåer fra rotnoden til en hver løvnode.
Databasen sørger for at indeksen alltid er oppdatert og at treet er balansert etter hver create, delete eller update. Derfor medfører hver indeks en overhead ved alle skriveoperasjoner på tabellen.
¶Oppslag i indeksen
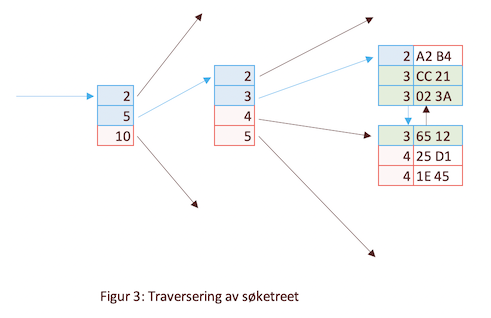
Figur 3 viser et oppslag på department_id=3. Oppslaget begynner på starten av rotnoden og leter sekvensielt etter en verdi som er >= 3. I dette eksemplet er det 5. Søket fortsetter på samme måte i gren-noden som 5 peker på. Vi finner her verdien 3 og følger pekeren til det neste nivået i treet. Søket gjentas på samme måte til det treffer en løvnode. Resultatet av søket vil være 0 eller flere løvnoder som matcher kriteriet. Hvis det indekserte feltet er unikt er vi garantert å få høyst ett treff.
Det viktigste poenget her er at traversering av treet er veldig raskt fordi antall nivåer i treet kun vokser med logaritmen til antall innslag i indeksen. I praksis betyr det at en indeks med flere millioner innslag vil ha en tredybde på kun 4-5.
Til tross for at traversering av indeks-treet alltid er raskt, er det flere faktorer som avgjør om et gitt oppslag er raskt i praksis. Vi kan dele et indeksoppslag i følgende operasjoner (terminologi fra Oracle-databaser):
- INDEX UNIQUE SCAN
Kun traversering av søketreet med ett og bare ett treff i indeksen. Alltid raskt.
- INDEX RANGE SCAN
Traversering av søketreet og deretter sekvensiell lesing av påfølgende indeksverdier som matcher søkekriteriet.
- TABLE ACCESS BY ROWID
For å hente ut data fra andre kolonner enn den indekserte må databasen finne den faktiske tabellraden ved hjelp av ROWID. Dette er en random-access-operasjon og kan være treg avhengig av hardware. Antall slike oppslag avgjøres av hvor mange treff vi fikk i indeksen. Hvis det er snakk om tusenvis av treff i en INDEX RANGE SCAN så kan dette ta veldig lang tid. Faktisk så er en TABLE ACCESS BY ROWID mer kostbar enn å lese sekvensielt fra tabellen. Det forklarer hvorfor en spørring som tilsynelatende burde brukt en indeks velger en full table scan i stedet. Rett og slett fordi antall tabelloppslag ville gjort det tregere enn å lese hele tabellen sekvensielt.
Det er derfor viktig å forstå at selv om vi gjør oppslag på en indeksert kolonne, er det ingen garanti for at spørringen blir rask. Antall innslag i indeksen som må leses sekvensielt og deretter antall tabelloppslag vil være avgjørende.
¶Enkle indekser
Nå som vi vet hvordan indeksen fungerer kan vi se på eksempler på ulike spørringer og hvordan databasen bruker indeksene.
Unike indekser
Primærnøkkelen til en tabell får automatisk en egen indeks med kun unike verdier (unique index). Oppslag på primærnøkkel eller andre kolonner med en unique constraint er alltid raske fordi databasen aldri trenger å følge kjeden av løvnoder (INDEX UNIQUE SCAN). Den følgende spørringenen bruker ordrens id til å slå opp kundenummer og ordredato fra ordre-tabellen:
select customer_id, order_time
from order_t
where id = 34;
Hvis vi legger på nøkkelordet explain før spørringen får vi se databasens eksekveringsplan (også kjent som explain plan) som viser hvilke steg databasen planlegger å gjøre for finne dataene, hvor lang tid den estimerer det vil ta og hvor mye data den forventer å hente:
Index Scan using order_t_pkey on order_t (cost=0.42..2.65 rows=1 width=16)
Index Cond: (id = 34)
Denne eksekveringsplanen, som er fra en PostgreSQL-database, viser at det vil bli gjort en index scan, at indekskriteriet er id = 34 og at den forventer kun 1 matchende rad. Fra tidligere vet vi at dette innebærer traversering av indekstreet (raskt) og oppslag i tabellen basert på ROWID (raskt så lenge det bare er 1 som i dette tilfellet).
¶Flere treff
For alle andre kolonner enn primærnøkler lager man en enkel indeks på f.eks. department_id i tabellen order_t med SQL-uttrykket:
create index department_id_idx on order_t (department_id);
For å hente alle ordre tilhørende en avdeling kan vi bruke følgende spørring:
select customer_id, order_time
from order_t
where department_id = 2;
Dette gir følgende explain plan:
Bitmap Heap Scan on order_t (cost=636.25..37841.87 rows=49254 width=16)
Recheck Cond: (department_id = 2)
-> Bitmap Index Scan on department_id_idx (cost=0.00..623.93 rows=49254 width=0)
Index Cond: (department_id = 2)
Dette gir en litt annerledes plan enn den forrige. Denne planen tilsvarer det vi tidligere definerte som en INDEX RANGE SCAN etterfult av mange TABLE ACCESS BY ROWID. Når antall rader blir mange gjør en Postgres en optimalisering der dette deles i to operasjoner: Først hentes alle resultatene fra indeksen (Bitmap Index Scan). Deretter sorteres disse etter hvor radene i tabellen fysisk er lagret og deretter henter den alle verdiene fra tabellen. Dette minimerer antall random-access-operasjoner.
Legg merke til hvor mye cost-indikatoren har økt. Cost sier noe om hvor lang tid databasen forventer å bruke på å utføre spørringen. cost=636.25..37841.87 betyr at operasjonen på denne linjen har en oppstartskostnad på 636.25 og en totalkostnad på 37841.87 (den vi er mest interessert i nå). Denne costen er den cumulative costen til denne operasjonen og de foregående. Enheten er ikke definert, men en operasjon med cost=100 er 100 ganger tregere enn en med cost=1. Vi ser altså at dette indeksoppslaget er mer enn 14000 ganger tregere enn i stad og det er forventet å finne 49254 rader i indeksen.
¶Sammensatte indekser
Som nevnt innledningsvis kan en indeks inneholde verdier fra flere kolonner. Dette gjør at vi kan lage indekser som er skreddersydde til enkelte typer oppslag og som likevel er generiske nok til å kunne brukes av ulike spørringer. Som vi så i forrige eksempel så var det ganske kostbart å spørre etter alle ordrene for en hel avdeling. Kanskje vi egentlig bare er interessert i ordrene for i dag? Hvis vi legger til order_time for i dag i where-clausen til spørringen bør det snevre inn søket ganske mye:
select customer_id, order_time
from order_t
where department_id = 2 and order_time >= '2020-11-03' and order_time < '2020-11-04';
Bitmap Heap Scan on order_t (cost=623.94..38075.84 rows=36 width=16)
Recheck Cond: (department_id = 2)
Filter: ((order_time >= '2020-11-03 00:00:00+00'::timestamp with time zone) AND (order_time < '2020-11-04 00:00:00+00'::timestamp with time zone))
-> Bitmap Index Scan on department_id_idx (cost=0.00..623.93 rows=49254 width=0)
Index Cond: (department_id = 2)
Som forventet har det estimerte antall rader gått dramatisk ned fra 49254 til 36. Men det som er overraskende er at totalkostnaden til spørringen nesten ikke har gått ned i det hele tatt. Explain-planen gir oss hintet. Den første operasjonen Bitmap Index Scan er helt identisk med forrige gang. Det vil si at vi finner nøyaktig like mange innslag i indeksen. Noe som er forventet. I neste operasjon ser vi at det har dukket opp et ekstra filter med order_time kriteriet vårt under Bitmap Heap Scan. Det betyr at det først når vi gjør selve tabelloppslaget vi kan sjekke om ordren er fra i dag. Og det gir jo mening siden order_time ikke finnes i indeksen vår.
Vi trenger en sammensatt indeks med både department_id og order_time:
create index department_id_order_time_idx on order_t (department_id, order_time);
Med den samme spørringen som før får vi nå en helt annen plan:
Index Scan using department_id_order_time_idx on order_t (cost=0.43..42.31 rows=37 width=16)
Index Cond: ((department_id = 2) AND (order_time >= '2020-11-03 00:00:00+00'::timestamp with time zone) AND (order_time < '2020-11-04 00:00:00+00'::timestamp with time zone))
Voila! Planen sier samme antall forventede rader, men en cost som er nesten 1000 ganger lavere. Nå kan databasen evaluere begge kriteriene kun ved å lese fra indeksen. Og ikke nok med det: Så lenge første kriteriet er likhet (=) og det andre et intervall så vil traversering av indekstreet lede rett til den første løvnoden som matcher begge kriteriene. Dermed trenger den ikke engang besøke alle løvnoder med department_id = 2. Deretter følges alle påfølgende løvnoder som oppfyller order_time-kriteriet. Til slutt gjøres et minimum av TABLE ACCESS BY ROWID for å hente de kolonnene som ikke ligger i indeksen.
Husk å alltid indeksere for likhet (=) først og intervaller (<, >) til slutt. Eksemplet over hadde vært langt mindre effektivt hvis vi hadde byttet rekkefølgen på kolonnene i indeksen.
INDEX ONLY SCAN
Hvis indeksen i eksemplet over også dekket kolonnen customer_id (i tillegg til department_id og order_time) så hadde ikke databasen trengt å lese fra tabellen i det hele tatt siden alle kolonnene allerede er tilgjengelig i indeksen. Dette kalles en INDEX ONLY SCAN og kan være et nyttig verktøy for å optimalisere enkelte kritiske spørringer.
¶Funksjonsindekser
En funksjonsindeks er en indeks der alle verdier fra den indekserte kolonnen transformeres av en funksjon før den lagres i indeksen. For eksempel date_trunc('day' order_time) som nuller ut all tidsinformasjon fra en timestamptz. Funksjonen kan være en vilkårlig transformasjon, men det avgjørende er at en funksjonsindeks kun kan brukes hvis kriteriet i where-clausen matcher definisjonen av indeksen. For eksempel gitt følgende indeks:
create index order_date_idx on order_t (date_trunc('day', order_time));
så vil følgende uttrykk bruke indeksen:
where date_trunc('day', order_time) = '2020-11-03'::timestamptz`
mens dette vil ikke bruke den selv om verdien vi sammenligner med finnes i indeksen:
where order_time = '2020-11-03'::timestamptz`
¶Delvise indekser
Hvis vi indekserer en kolonne der vi kun er interessert i et subset av verdiene kan vi spare lagringsplass ved å lage en delvis indeks (partial index). Dette gjøres ved å legge inn en where-clause i indeksdefinisjonen. Hvis vi for eksempel har et flagg som brukes av en faktureringsprosess til å hente kun ordre som ikke er fakturert kan vi lage følgende index:
create index not_invoiced_idx on order_t (invoiced) where invoiced = false
Denne indeksen vil kun brukes hvis spørringens where-clause inneholder kriteriet invoiced=false. Fordelen med en slik indeks er at den vil forbli liten selv om vi har millioner av ordre som allerede er fakturert (invoiced = true).
¶Join
I denne omgang blir det litt for omfattende å gå i detalj på joins. Men det er verdt å nevne kort hvordan indeksering påvirker ytelsen til ulike joins.
Nested loop join
Nested loops er akkurat som navnet antyder. Databasen gjør først et uttrekk fra tabellen på den ene siden av joinen og for hvert resultat gjør et oppslag i den andre tabellen basert på join-kriteriet. Dette vil ofte være på primærnøkkel eller fremmednøkkel slik at en nested-loop-join vil ha nytte av at kolonnene som inngår i join-kriteriet er indeksert.
Hash join
En hash-join derimot laster resultatet fra den ene siden inn i en hash-tabell i minnet som kan brukes til svært raske oppslag når man går gjennom resultatet fra den andre siden. I dette tilfellet hjelper det ingenting med indekser på join-kolonnene. I dette tilfellet er det kun indekser på uavhengige where-kriterier som hjelper. I tillegg hjelper det å ha færre kolonner i select-delen for å redusere datamengden i hash-tabellen.
¶Oppsummering
Følgende punkter er viktig om indekser i SQL-databaser
- Gode indekser er avgjørende for ytelsen til databasen
- Det er utvikleres jobb å lage indekser
- En index består av et søketre og en dobbeltlenket liste av løvnoder
- Traversering av søketreet er lynraskt
- Sekvensielt søk i løvnodene er ganske raskt
- Oppslag i selve tabellen er tregt
- Hver indeks medfører overhead ved hver skriveoperasjon i tillegg til at de tar opp plass
- Én indeks som dekker alle kolonnene i where-clausen er raskere enn individuelle indekser på hver kolonne
- En “treg indeks” betyr at for mange løvnoder måtte traverseres sekvensielt og/eller for mange tabelloppslag
Hvis du ønsker å lære mer om indekser så anbefales boken Use the index Luke på det varmeste. Den er også hovedkilden til dette innlegget.
