¶Plutselig alt for mye data å vise for frontenden
Nylig fikk vi et glimrende grunnkurs i SQL-indekser og spørringene våre bruker indekser og går lynrask med lav kost. Den nye utfordringen vår er nå at både systemet og bruken av det øker, det er flere som bestiller fra oss og antall ordre øker kraftig hver eneste måned. Vi trenger å implementere paginering i frontend, men hvordan kan vi optimalisere spørringene våre mot databasen for at frontend enkelt kan spørre om en side med et gitt antall resultater?
Første forsøk med OFFSET og LIMIT
De fleste relasjonsdatabaser støtter en eller annen form for OFFSET og LIMIT, og det ser også ut som det enkleste å implementere når vi vil dele opp resultatsettet vårt. La oss prøve!
OFFSET 10betyr at vi vil ha rader etter rad nummer 10 i resultatsettetLIMIT 10betyr at vi ønsker maksimalt 10 rader i resultatsettet
Det finnes en tillegssyntaks som gjør akkurat det samme, vi kan bruke
OFFSET 10 FETCH NEXT 10 ROWS ONLYfor å hente “side 2” av resultatsettet, det blir det samme somOFFSET 10 LIMIT 10
La oss teste hvordan dette fungerer. Vi har en database med ordre, hver ordre tilhører en avdeling og har en tilhørende dato. Så la oss hente all ordre for avdeling 1 den 30. november 2020.
select id, package_id
from order_t
where department_id = 1
and order_time >= '2020-11-30'
and order_time < '2020-12-01'
OFFSET 0 LIMIT 10
La oss se på planen for spørringen:
Limit (cost=0.42..19.34 rows=10 width=31)
-> Index Scan using order_t_department_delivery_time_id_idx on order_t (cost=0.42..1419.00 rows=750 width=31)
Index Cond: ((department_id = 1) AND (order_time >= '2020-11-30 00:00:00'::timestamp without time zone)
AND (order_time < '2020-12-03 00:00:00'::timestamp without time zone))
Dette ser bra ut, kosten er lav og vi treffer indeksen vår, men det er en viktig ting vi har glemt her:
- For å bruke denne type paginering MÅ det være en deterministisk sortering av resultatsettet, hvis ikke kan vi ikke garantere at vi får ut alle data
Så la oss skrive om spørringen og prøve igjen. Vi sorterer på de kolonnene som finnes i indeksen, department_id, order_time og id
Det er viktig at kolonnene i en order by sorteres i samme rekkefølge som de er definert i indeksen, dette fordi en indeks alltid er sortert på de kolonner som er definert i indeksen.
select id, package_id
from order_t
where department_id = 1
and order_time >= '2020-11-30'
and order_time < '2020-12-01'
order by department_id, order_time, id
OFFSET 0 LIMIT 10
Hjalp det å sortere og hente ut færre kolonner?
Limit (cost=0.42..19.58 rows=10 width=31)
-> Index Scan using order_t_department_delivery_time_id_idx on order_t (cost=0.42..479.44 rows=250 width=31)
Index Cond: ((department_id = 1) AND (order_time >= '2020-11-30 00:00:00'::timestamp without time zone)
AND (order_time < '2020-12-01 00:00:00'::timestamp without time zone))
Nå vil vi forsøke å hente side 10, da endrer vi bare OFFSET til 100 og kjører spørringen igjen, vi får da denne planen:
Limit (cost=192.03..211.19 rows=10 width=31)
-> Index Scan using order_t_department_delivery_time_id_idx on order_t (cost=0.42..479.44 rows=250 width=31)
Index Cond: ((department_id = 1) AND (order_time >= '2020-11-30 00:00:00'::timestamp without time zone)
AND (order_time < '2020-12-01 00:00:00'::timestamp without time zone))
Vi returnerer fortsatt bare 10 rader, MEN kosten har gått opp fra 19.58 til 211. La oss se hva kosten blir når vi henter ut data enda lenger bak i datasettet:
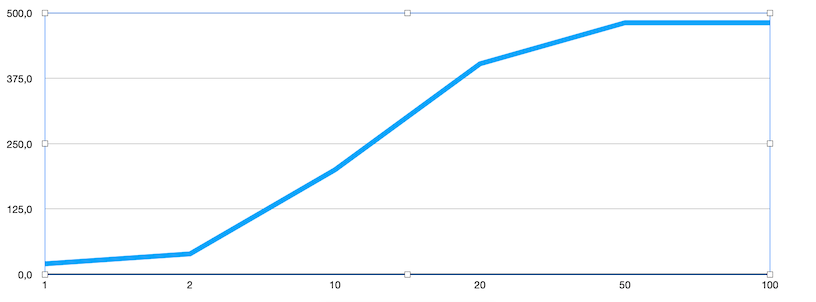
Som grafen viser så øker kosten for hver enkelt side, dette er ikke bra. I dette tilfellet flater kurven ut etter side 100 pga datasettets størrelse, dersom det er mer data vil kosten øke enda mer utover.
Konklusjon med bruk av OFFSET og LIMIT
Kosten øker jo lenger bak i datasettet vi ønsker å finne data, dette blir potensielt veldig tregt, selv om vi har og bruker indekser.
OFFSET og LIMIT søker gjennom hele datasettet for å finne de radene som skal taes med i resultatsettet. Kosten vil derfor øke jo lenger bak i datasettet man ønsker å finne data.
¶Andre forsøk - søke-metoden
Indeksen vi har laget inneholder alle de tre kolonnene vi benyttet for å sortere, hva om vi vet hva høyeste id på forrige side var, kan vi da kanskje bruke denne? For første side så blir spørringen lik den vi hadde:
select id, package_id
from order_t
where department_id = 1
and order_time >= '2020-11-30'
and order_time < '2020-12-01'
order by department_id, order_time, id
LIMIT 10
Dette fungerer på første side, men hva om vi vil se neste side? Eller side 5? La oss prøve å implementere dette på en måte hvor vi bare henter neste eller forrige side, uten å la oss hoppe fra side 1 til side 5.
¶Bruk høyeste id fra forrige spørring til å hente ut data
Utehentingen fra første test med OFFSET og LIMIT gir oss ikke et resultat hvor id er sortert stigende, vi må derfor gjøre om sorteringen og dermed også lage en ny indeks. Vi lager en ny indeks hvor vi sørger for at id er første kolonne:
create index concurrently if not exists order_t_id_department_delivery_time_idx on order_t (id, department_id, order_time)
Første side vil vi nå hente ut slik:
select id
from order_t
where department_id = 1
and order_time >= '2020-11-30' and order_time < '2021-12-01'
order by id, department_id, order_time
limit 10
Denne går veldig fort og fordi indeksen allerede er sortert trenger ikke databasen å sortere resultatet:
Limit (cost=0.43..107.92 rows=10 width=24)
-> Index Only Scan using order_t_id_department_delivery_time_idx on order_t (cost=0.43..86390.79 rows=8037 width=24)
Index Cond: ((department_id = 1) AND (order_time >= '2020-11-30 00:00:00'::timestamp without time zone)
AND (order_time < '2021-12-01 00:00:00'::timestamp without time zone))
Vi blir nå avhengige av data fra forrige side når vi nå skal hente neste og vi må legge til and id > :previousId i spørringen.
Planen endrer seg til dette:
Limit (cost=0.43..122.88 rows=10 width=24)
-> Index Only Scan using order_t_id_department_delivery_time_idx on order_t (cost=0.43..30795.53 rows=2515 width=24)
Index Cond: ((id > 3294128) AND (department_id = 1)
AND (order_time >= '2020-11-30 00:00:00'::timestamp without time zone)
AND (order_time < '2021-12-01 00:00:00'::timestamp without time zone))
Dette ser lovende ut. La oss prøve å hente ut data og sammenligne søke-metoden med OFFSET-metoden:
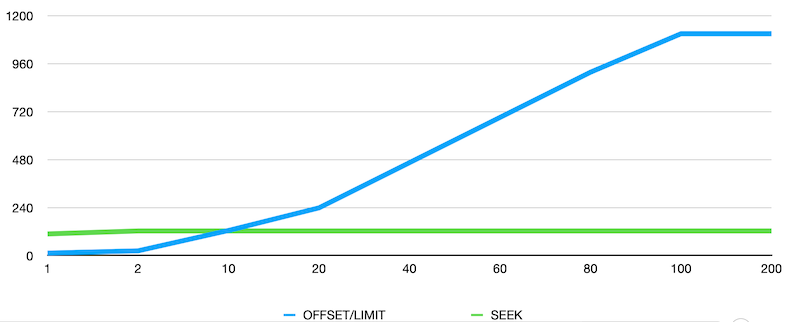 Dette ser jo veldig veldig bra ut. Forskjellen blir såpass stor her at det kan nok lønne seg å hente data på denne måten.
Dette ser jo veldig veldig bra ut. Forskjellen blir såpass stor her at det kan nok lønne seg å hente data på denne måten.
¶Konklusjon
Vi bør være forsiktige med å bruke LIMIT og OFFSET uten å sjekke ytelsen, de første sidene kan gå raskt, men når vi blar oss lang frem eller langt tilbake i et datasett så vil kosten øke betrakelig.
I tillegg dukker det opp andre utfordringer når man begynner å joine inn flere tabeller. Hva hvis hver ordre har en eller flere pakker? Hva hvis hver av pakkene har vekt? Kanskje hver pakke har noen hendelser tilknyttet seg?
Når flere rader i resultatsettet representerer en av ordrene vi vil ha ut, så kan vi ikke lenger bare bruke limit 200 for i de 200 radene vi får ut kan vi risikere å få samme id flere ganger.
Dette får vi se mer på en annen gang.
¶Oppsummering
Hva er viktig å tenke på når vi skal splitte opp et resultatsett for best mulig ytelse:
- Deterministisk sortering av resultatsettet, vi må være sikre på å få ut de samme radene for den samme spørringen hver gang.
- Dobbeltsjekk at spørringer bruker indekser, ved endringer i where-clausen eller order by så bør spørringene sjekkes på nytt
- Bruk gjerne et online-verktøy for å visualisere hvordan spørringer utføres, sånn som dette PEV, eller min favoritt pgMustard
- OFFSET og LIMIT må søke gjennom hele datasettet for å finne de radene som skal taes med i resultatsettet. Kosten vil derfør øke jo lenger bak i resultatsettet man ønsker å finne data.
- Anbefaler å lese bloggen Use the index, Luke dersom du vil lære enda mer om ytelse i databaser
